데이터과학과 인공지능
- 2 mins목적
데이터과학과 인공지능 두 개의 과목을 이번 학기에 수강했다.
학점을 잘 받으면 좋겠지만 잘 받는 것과는 무관하게 이 분야에 내가 어느정도의 흥미가 있는지에 대한 호기심을 풀기 위함이었다.
배운 내용의 차이점
- 데이터과학: 많은 데이터들로부터 정보를 추출하는 여러가지 테크닉을 배웠다.
- 인공지능: 인공지능의 한 부분인 딥러닝에 대해 배웠다.
데이터과학
종강한 지금 생각해봐도 알고있으면 좋을만한 지식을 배워서 좋았다.
그런데 내가 자주 접한 분야가 아니기도 하고 처음 알게된 내용이 많아서 다시 코드를 처음부터 짜라고하면 라이브러리 없이는 꽤 고생할 것 같다. 그래서 나중에 코드는 다 잊더라도 이론만 기억하고 있어도 만족스러울 것 같다.
프로젝트1
단순한 프로그래밍 프로젝트여서 할 말이 없다. standard input, output 이용해서 대용량 데이터 처리하는 것
프로젝트2
기존까지 배운 내용들을 토대로 학생 신체데이터를 분석하는 거였다. linear regression 하는 것이 프로젝트의 목표였던 것 같다.
프로젝트3
기존까지 배운 내용들을 토대로 영화추천 시스템을 만드는 것이었다. 이미 입력된 별점 데이터들을 이용해서 Matrix factorization 하는 것이었는데 latent factor model 을 이용했다. 마지막으로 PCA 이용해서 visualization 을 통해 잘 예측했는지 검증하는 것까지가 프로젝트의 목표였다.
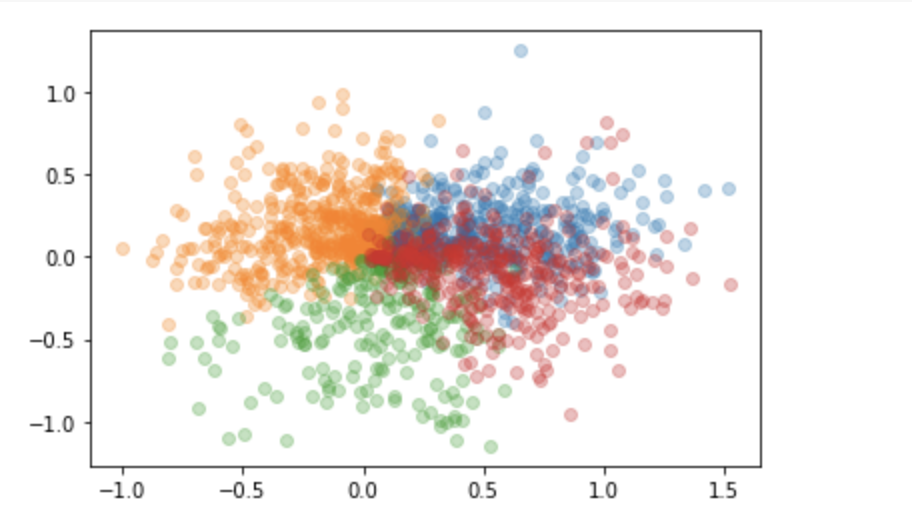
KNN 으로 clustering 하고 내 코드 기준 rank 10 인 데이터를 2 차원으로 축소해서 보면 사진처럼 나온다.
개인적으로 인공지능을 데이터과학 들은 후 흥미를 붙이고 들었으면 어땠을까라는 고민을 했지만 이미 늦었다.
인공지능
마찬가지로 좋은 지식들을 배웠다.
거의 종강할 때쯤 흥미가 생겨서 열심히 하려했지만 개인적인 사정으로 더 열심히 하지 못해서 아쉬웠다.
중간고사
기말고사에 비해 수업을 집중해서 들어서 수업들은 내용으로만 시험을 봤다.
하지만 틀린 답을 고르면 감점하는 것이 있어서 그런지 생각했던 점수보다 결과가 안나왔다.
캐글
시간을 잘못 써서 epoch 를 모두 못 돌리고 제출해서 최적화를 안한 모델의 성능이 나왔다. 나중에 따로 돌려보니 예측률이 70% 초반으로 나왔는데 최적화를 안한 모델과 그렇게 큰 차이가 나지도 않았다. 한 7%정도? 아마 normalize 를 통해 일반호 성능을 높였지만 padding 을 data 들에 추가한 것ㅇ 잘못된듯하다 트레이닝 데이터를 가공을 잘못했다. 오히려 역효과가 나도록.
예측 성능이 좋은 모델을 암기해서 참여했다면 높은 점수를 받았을 것 같기도한데 그 때는 다른 과목에 더 집중했다. 아쉽다.
기말고사
공부한만큼만 점수가 나온 것 같다. 즉, 결과가 좋지 않다. 교수님이 수업 신청기간 때 말씀한 내용인 ‘시간을 투자하지 못할거면 다른 수업 듣는 것을 추천한다’ 가 기억났고 만약 이 과목에만 집중했다면 결과가 크게 달랐을까? 라는 고민을했다.
마무리
사실 깊게 이해하려면 되게 어려운 분야들이기도 하고 이미 라이브러리들이 있는 것을 잘 활용할 줄만 안다면 그렇게 어려운 분야도 아니기도 하다. 그런데 흥미가 줄었으니 원래 하던 것이나 열심히 하자, 값진 경험이었다.